【概要編】替え歌合成システム「TalSing」に関するあれこれをまとめる

目次
はじめに | “Talk” + “Sing” = TalSing
約半年前、大学のオープンキャンパスで使用する研究室のデモ展示として制作を始めたのがきっかけだった、替え歌合成システム「TalSing」
(もっとも、当時は名前すらついていない、今となってはプロトタイプだが)
今回はその「TalSing」について、詳しいアルゴリズムや現状の性能、そしてこれから改善が必要とされる点などを備忘録的にまとめようと思う。
システムのソースコードは以下のリンクからダウンロード可能です。
特に難しいセットアップなどはないので是非お手元で動かしてみてください!
GitHub:https://github.com/TGfms/TalSing
当記事はシステムの概要を説明した【概要編】です。
実際に開発を進める際は、具体的なファイル構成や楽曲の追加方法を説明した
【実践編】も併せてお読みください。
ちなみにこのプロジェクトに関する分担を明らかにしておくと、音声分離とGUI設計の初期構想、システムに使用した一部の楽曲を除く全て(当記事の作成や動画・音楽編集、メインプログラマ)を担当した。半年越しとはなりましたが、研究室同期をはじめ協力してくれた方、ありがとうございました🙇♂️
まず、使い方について解説した下の動画を参照してもらいたい。
正直動画を見るまでもないほどシンプルなシステムではあるものの、興がのってしまい当初の予定以上に力の入った動画になってしまったので、「しょうがない、一回見てやるか…」くらいのノリで一度覗いてみてほしい。
いかがだっただろうか。「TalSing」はその名の通り(”Talk”+”Sing”)「喋るだけで替え歌が作れる」をウリとしたシステムである。
基本的な使い方は動画を見ていただければ分かると思うので、ここからはその具体的なアルゴリズムに触れていく。
音声収録部 | 2本のマイク、それ即ちエゴ
はじめに、当システムの一連のフローを以下の図に示す。
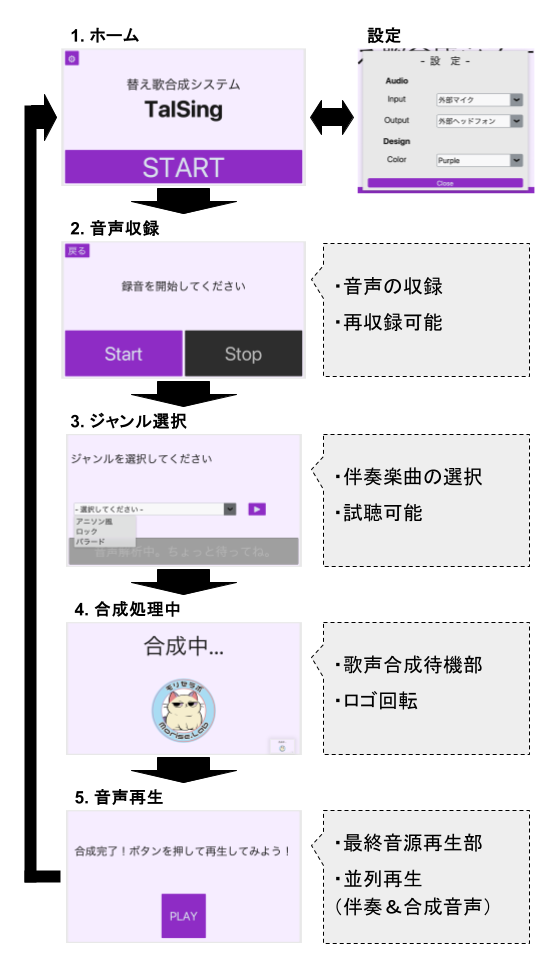
まず触れたいのが、2フレーム目の音声収録部だ。
当システムには音声の入力方法が2つある。1つは動画と同じ、普通にマイク1本で入力する方法。
そして2つ目が、マイク2本で収録し独立成分分析(Independent Component Analysis; ICA)を行う方法である。
独立成分分析に関して詳細な説明は省くが、簡単にいえば2つ(またはそれ以上)の音声を元に「音声A」と「音声B」、今回でいえば「ノイズ」と「ノイズでない音声」を抽出する音源分離手法の1つである。
今回この手法を採用した経緯としては、このシステムがオープンキャンパスのデモであるという前提がある。オープンキャンパス当日は多くのゲストで賑わい、収録の際には余計なノイズが入ることが予想された。したがって独立成分分析を用いることで、より安定した音声認識を目指した。
というのは半分建前であり、独立成分分析は昔ながらの手法である(1990年代には確立していたとか)。AI技術が発展した今となってはマイク1本で収録した音声からノイズを分離することなど容易である。
つまるところ、マイクをわざわざ2本用意して昔の手法を採用するなど、「なんかマイク2本使ってる。すごそう。」とゲストに思わせるためのエゴでしかない。
(とはいえ、検証をしていないのではっきりとはいえないが、もしかしたら所要時間等で当手法に軍配が上がる可能性もなくはない)
歌声合成部 | 全ての鍵は楽譜にあり
次に、当システムの一番の目玉、歌声合成処理部に触れていく。システムの外観的にはイヌ(という名の猫)がくるくる回っているときに裏で行われている処理である。
もっとも、歌声合成自体はNNSVSという既存の歌声合成ライブラリを用いているため、今回はそれを利用するにあたって必要となる、入力テキストを反映させた楽譜作成アルゴリズムを解説する。
(NNSVSは私個人の研究でも大変お世話になり仲良くなっているので、また別の機会に記事にするかもしれない…)
楽譜作成部の入力は音声から取得した日本語テキストとベースとなる楽譜、出力は新規楽譜ファイルであり、作成のフローは下図の通りである。

まず前画面で選択されたジャンルに対応する、あらかじめ用意したベースとなる楽譜を読み込み、各種情報を取得する。例として以下のような楽譜を読み込んだとする。

参考までに、これをピアノで弾いたのがこちら。
ズバリ、デモ動画中で選択したジャンル「アニソン風」の楽譜である。
そしてxmlinfoクラスに格納される、この楽譜から取得された情報が以下である。各情報については図中に簡単な説明があるのであわせて参照されたい。
- num_measure: 10
- num_note: 35
- num_mora: 32
- durations_mora : [1, 1, 2, 2, 1, 2, 2, 1, 2, 2, 2, 4, 2, 2, 1, 2, 2, 1, 4, 1, 1, 5, 2, 2, 1, 1, 2, 2, 2, 2, 2, 6]
- durations_mora_splitable : [1, 1, 2, 2, 1, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, 1, 1, 1, 5, 2, 2, 1, 1, 2, 2, 2, 2, 2]
- breathbatch : [12, 10, 10]
- breathbatch_start_measure : [1, 4, 8]
いくつか補足をすると、
・durations_mora_splitableのカウント対象としない「上げ弓記号」とは、例えば上記の楽譜の最後のノートの上部についているものである(計3個)。これは歌として伸ばした方が良いと思われるノートを確実に分割させないための措置である。(試しに指定する場合としない場合で合成してみると、歌としての自然性の違いに気づくだろう)
・breathbatchで使用する「ブレス記号」とは、例えば上記の楽譜の上から2段目の最右のノートのすぐ左にある記号である(計2個)。今回のシステムで生成される音声ではブレスを行わないが、下記で説明する、文節を考慮した譜割り作成にあたって必要となる。
次に、音声から抽出されたテキストをもとにテキスト情報をtextinfoクラスに格納する。
今回は例として、デモ動画で入力した文章「喋るだけで歌を作れる替え歌合成システム『TalSing』のデモ動画です。」を入力した場合を考える。
- kanatext : シャベルダケデウタガツクレルカエウタゴーセーシステムトーシングノデモドーガデス
- mora_list : [‘しゃ’, ‘べ’, ‘る’, ‘だ’, ‘け’, ‘で’, ‘う’, ‘た’, ‘が’, ‘つ’, ‘く’, ‘れ’, ‘る’, ‘か’, ‘え’, ‘う’, ‘た’, ‘ご’, ‘ー’, ‘せ’, ‘ー’, ‘し’, ‘す’, ‘て’, ‘む’, ‘と’, ‘ー’, ‘し’, ‘ん’, ‘ぐ’, ‘の’, ‘で’, ‘も’, ‘ど’, ‘ー’, ‘が’, ‘で’, ‘す’]
- bunsetsu_list : [‘しゃべる’, ‘だけで’, ‘うたが’, ‘つくれる’, ‘かえうた’, ‘ごおせえしすてむ’, ‘とおしんぐの’, ‘でもどおがです’]
- bunsetsu_list_num : [3, 3, 3, 4, 4, 8, 6, 7]
各情報は以上のようになる。これについても図中で簡単な説明をしている。
ちなみに「モーラ」とは日本語の拍に対応する単位であり、上記の mora_list に格納されているのがそれぞれ1モーラである。
さらにちなみに、「モーラ」をもう一段階分解したのが「音素」である。/k/, /a/, /e/, /u/, /t/ のように表記し、それ以上に分解できない日本語の音韻的最小単位である。
ここからはいよいよ入力を反映した楽譜ファイルの編集を行う。
楽譜作成部を示した上図フローの中の「楽譜ファイル編集」と書かれた部分の処理を図式したのが以下である。
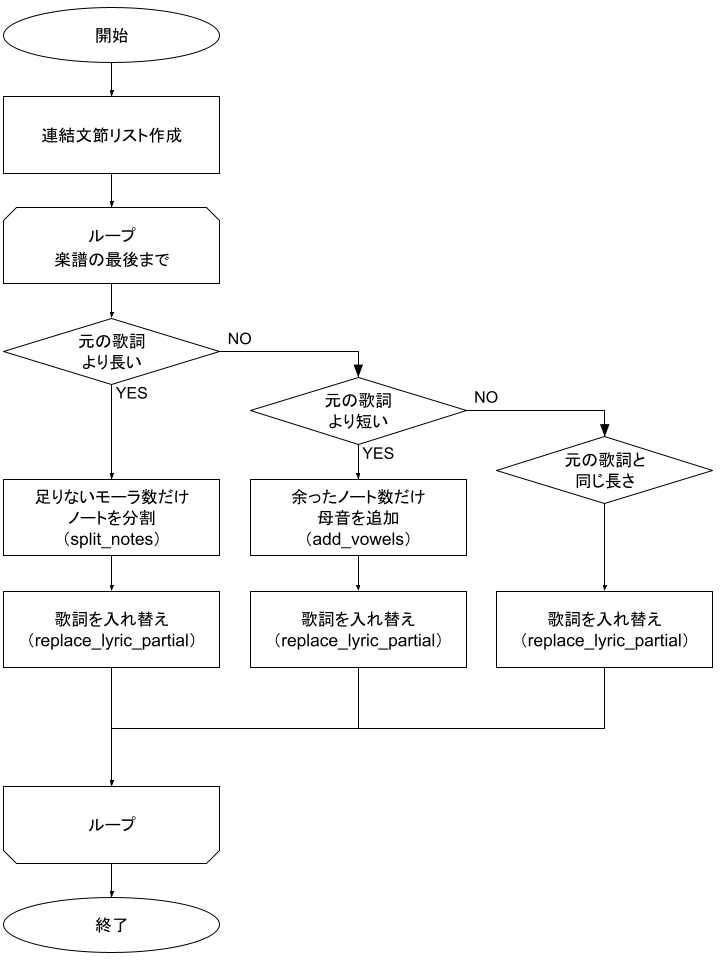
順に上から処理を追っていく。
連結文節リスト作成では、ブレス記号で区切られた区間それぞれに対応する歌詞を作成する。
具体的には、各区間のモーラ数以上のモーラが割り当てられるように文節を連結させていく。
今回の場合、
・breathbatch : [12, 10, 10]
・bunsetsu_list_num : [3, 3, 3, 4, 4, 8, 6, 7]
であることから、最初の連結文節のモーラ数は
3 + 3 + 3 + 4 = 13 (>= 12)
であり、連結文節は「しゃべるだけでうたがつくれる」となる。
同様の処理を楽譜の最後まで行うと、連結文節を格納したリスト(connected_bunsetsu_list)は次のようになる。
- connected_bunsetsu_list : [‘しゃべるだけでうたがつくれる’, ‘かえうたごおせえしすてむ’, ‘とおしんぐのでもどおがです’]
* * *
その後はノートの長さを調節するループ処理に入る。
ここまでに取得された情報をまとめると、
- a) ブレス記号で区切られた区間のベース楽譜のモーラ数(breathbatch) : [12, 10, 10]
- b) 連結文節リスト(connected_bunsetsu_list) : [‘しゃべるだけでうたがつくれる’, ‘かえうたごおせえしすてむ’, ‘とおしんぐのでもどおがです’]
- c) 連結文節リストの各モーラ数 : [13, 12, 13]
である。
各ループでは、aとcのn番目を比較し、「元の歌詞より長い場合」と「元の歌詞より短い場合」と「元の歌詞と同じモーラ数の場合」で処理が分岐する。
i) 元の歌詞より長い場合
元のモーラ数よりはみ出ている数だけノートを分割する(split_notes関数)。分割するノートはduration値が大きいノートから優先的に選ばれる。
例えば該当区間のノートのduration値が[2, 2, 1, 2, 4, 2, 1]であったとき、
・はみ出ている数が1なら [2, 2, 1, 2, 4, 2, 1] → [2, 2, 1, 2, 2, 2, 2, 1]
・はみ出ている数が2なら [2, 2, 1, 2, 4, 2, 1] → [1, 1, 2, 1, 2, 2, 2, 2, 1]
・はみ出ている数が3なら [2, 2, 1, 2, 4, 2, 1] → [1, 1, 1, 1, 1, 2, 2, 2, 2, 1]
のようにノートが分割される。
ii) 元の歌詞より短い場合
元のモーラ数より足りない数だけ母音を追加する(add_vowels関数)。母音は先頭から順に追加される。
例えば該当歌詞が「かえうた」の場合、
・足りない数が1なら 「かあえうた」
・足りない数が2なら 「かあええうた」
・足りない数が3なら 「かあええううた」
となる。
以上のi, iiの処理を終える、もしくは元の歌詞と同じモーラ数の場合、最後に歌詞を置き換えてループ終了である。
以上が現状の楽譜作成アルゴリズムの全貌であり、全処理が終わったファイルを保存して楽譜作成部は終了となる。以降はその楽譜をNNSVSに渡して歌声合成が開始される。
こうしてまとめると、かなり単純なアルゴリズムに思えるのではなかろうか。
これでもなるべく違和感が無くかつ安定した譜割りを実装したつもりだが、やはりまだ不完全なものであり、たまに歌声が生成されないなどのエラーは発生してしまう。
ここからは現状のアルゴリズムの改善点や、さらに魅力的なシステムにするための改良案をいくつかピックアップして紹介しようと思う。
譜割りアルゴリズム改善点 | 君たちはどう割り当てるか
把握している中で最も頻繁に発生してしまうエラーは、ノートを分割し過ぎてしまった結果ひとつのノートduration値が非常に小さくなってしまい、歌声合成時に発声不可能になってしまうことである。
前ページで説明した通り、現状のアルゴリズムでは、元の楽譜と入力のテキストに応じて、はみ出た数だけノートを分割している。
よって、例えば元の楽譜のモーラ数が5、入力の連結文節のモーラ数が15であった場合、15-5=10回ノートの分割が行われてしまう。元の楽譜にもよるが、このとき大概の場合はひとつのノート長が極端に短くなってしまい、正しく合成できないことが予想される。
このような事態に陥る可能性が高いのは、長いモーラ長の固有名詞が入力されたときである。そのような固有名詞を入力すると、文節に分割する際にひとつの文節が大きくなってしまい、それを用いて連結文節を作成するとどうしても長くなってしまうのである。
その他のエラーやあまり美しくない結果となってしまう事例は以下の通りである。
- 音声認識部で日本語以外の言語に識別されてしまうと、歌詞がnullになりエラー
- ベースの楽譜の歌詞よりも長い音声を入力すると、入らなかった文節は切り捨てられる(エラーではないが歌としては美しくない)
- 音声認識をミスり日本語としておかしい(品詞の不明な文字が列挙されるなど)文章が入力されると、文節に区切る際に大きいモーラ数となることがあり、上記のように極端に短いノートが生まれることがある(場合によってはエラー)
これらエラーの中には、譜割りアルゴリズムの改善以前に、適切なエラー処理を施すことで未然に防ぐことができそうなものもある。研究室の後輩でシステムの改良を行ってくれる人がいれば、まずはここから手をつけてみるのはいかがだろうか。
そもそも「文節に基づき歌詞を割り当てる」という現状の方法が、私が考えた譜割りアルゴリズムのひとつでしかない。そういう意味で、根本的なアルゴリズムから見直してみるのも大いにありである。君たちはどう割り当てるか。自分なりのアンサーを自由な発想で考えてみてほしい。
余談ではあるが、GUIスクリプトと合成や再生スクリプトは別スレッドで処理を行っていたために、オープンキャンパス当日にエラーでデモが中断されることがなかったのは意図しない救済であった。
色々なシステム改良案 | 味変し放題の秘伝のタレ
エラー対策とは別に、さらなる魅力的なシステムとするべく考えている改良案もいくつか紹介する。
まずはアクセントの考慮だ。
日本語の文章にはアクセントがあり、それによって自然に感じる音高の上下動はある程度絞られる。
例えば「おはよう」という歌詞にメロディをつけるとき、
・「お→は↗︎よ→う→」(上に弧を描くイメージのメロディ)
・「お→は↘︎よ→う→」(下に弧を描くイメージのメロディ)
このどちらが自然に聞こえるだろうか。是非試しに声に出してみて欲しいが、おそらく前者の方が自然に思えるのではないだろうか。これは普段の会話の中で発話する「おはよう」のアクセントにより近いのが前者であるためである。
このような歌詞とメロディの関係性は、実際の音楽制作の中でもごく当たり前に考慮されているものである。当システムでもこのようなアクセントを考慮した譜割りアルゴリズムを採用できれば、より自然な歌声が生成できるに違いない。
* * *
アクセントに関しては音高以外にも、メロディのリズムへの反映も考えられる。
例えば「あさって」という歌詞にメロディをつけることを考えてみる。


上図をそれぞれ発音してもらえれば分かると思うが、明らかにAのリズムが望ましいと思われる。Bはもはや「あーさて」という別の言葉に聞こえてしまう。しかしながら現状のシステムではアクセントを全く考慮しておらず、リズムもベースの楽譜に依存しているため、今回のBのように明らかに不自然なリズムだったとしてもそれに従わざるを得ない。
このように歌詞から最適なリズムを作成する可変リズム生成も有用であると考えられる。
* * *
より作曲的な発想としては、ハモリの生成も面白そうだ。
私自身作曲を行うため、身に沁みて重要性を理解しているつもりだが、ハモリがあるのとないのとでは曲のクオリティに雲泥の差が生まれると言っても良い。普段から聴き慣れた曲でも、慎重に聴いてみると意外とうっすらとハモリを歌っているケースは少なくない。そして、そのうっすら聴こえているハモリがメインメロディの信ぴょう性を高めているのだ。(せめてサビにはハモリを入れろ。との言葉をよく聞くし、私自身たいていの場合はその通りだと思う)
ハモリの生成は技術的には難しくない。あらかじめハモリ用の楽譜も用意しておき、譜割りを同じように行えば良いのだ。もっとも、メインとハモリふたつの音声を合成することになると合成に所要する時間は単純計算で2倍になるため、システム全体のユーザ体験を考えたときに2倍の時間を所用してまでハモリを生成する必要があるかは吟味する必要がある。
* * *
最後に、ミックス的な視点での改良案、EQ・コンプ等の実装もここに記しておく。
音楽において「ミックス」とはかなり広い言葉だが、楽曲にボーカルを混ぜる作業もそのひとつである。
その際にぶち当たる壁として、「曲からボーカルが浮いて聞こえる・埋もれて聞こえる」問題がある。そして当システムにおいても現状、それが起こっている。デモ動画を見返してみると分かるが、明らかに伴奏の曲からボーカルが浮いて聞こえる。(伴奏の音量を意図的に下げているので、今回に関してはボーカルが埋もれて聞こえることはないと思う)
そんなときに登場するのがEQ・コンプである。EQ・コンプとは、
- EQ…Equalizerの略。周波数特性を操作する目的で使われる基本的なエフェクト。
使用例)ボーカルがボヤボヤして聞こえるから低中域を少し下げるか… - コンプ…コンプレッサーの略。時間軸方向の音量変化を操作する目的で使われる基本的なエフェクト。
使用例)ボーカルのダイナミクス(音量差)が大きいからコンプをかけて潰すか…
上記の使用例はあくまで一例でしかないが、どちらも音楽制作において最も基本的なエフェクトのひとつである。これらを実装し適用させられれば実際の音楽制作の環境に近づき、最終音源のクオリティ向上に寄与することは間違いないだろう。
実際、当システムに似たことを行なっていた嵐の替え歌プロジェクトでは、音源生成時にミキシング・マスタリング処理を行なっていたらしい。
これと同等の品質のものを実装できるかは定かではないが、改良案のひとつとして控えておくのは悪くない。何事においても多角的な視点を持つことは重要である。
* * *
とまぁ挙げはじめればキリがないが、まだまだシステムの改良の余地は多分にある。
現状のシステムは、オープンキャンパスのデモという前提で作った割と間に合わせ(+その後のテコ入れ)のシステムである。GUIの工夫や処理の高速化など、上記の改良案の以外にもさまざまな面において未完成なシステムであることは言うまでもない。(当初は作成した楽譜を音源再生時に表示し、その上を再生バーが追うような見せ方ができれば…という話も挙がっていた)
ここまで読めば分かるように、当システムのほとんどは私個人の過去の経験をヒントに開発されたものであり、唯一の正解では決してない。これからこのシステムを使っていくであろう所属研究室の後輩たちには、ぜひ自由な発想で、失敗を恐れずチャレンジングで魅力的なシステム開発を行って欲しい。現状のシステムは、言わば「自分好みに味を変えることが許されている秘伝のタレ」のようなものなのである。
最後に
ここまで読んでくださりありがとうございました。
この記事では、替え歌合成システム「TalSing」の開発経緯から実際に中で行われている処理、そして今後の展望についてを体形的にまとめました。
記事自体には具体的なコードは載せず、なるべく当記事だけでシステムを理解できるように心がけました。理由としては、プログラミングにあまり馴染みがない人にも親しみを持って欲しいと考える他に、個人的には実際に開発を行う前に中で行われている内容を把握していた方がスムーズに開発を行えると思っているからです。システムの全体像を把握することにより、スクリプトや関数それぞれの立ち位置が分かり、より頭の中が整理される経験をこれまでにいくつも経験してきました。この記事がその助けになれば幸いです。
また、この章を除き文末表現は「である」調にしつつ半分口語表現のような言葉も散見されると思います。これは、「である」調を採用することでシンプルでありながらも人間味のある文章にしたかったためです。自身が好きな文章表現であることはもちろん、せっかくこの記事まで辿り着いてくれたからには途中で読むのを挫折してほしくない、という思いで書きました。もしよろしければ是非コメントをいただけると大変嬉しく思います。
最後になりますがTalSingに関して、ファイル構成やデータベースの追加についてなどまだ話していないことが少しあります。記事作成当初はそれらも含めてひとつの記事にしようと思っていましたが、ここまでの内容で思ったより長くなってしまったので、それらの内容については【実践編】とでも題してまた別の記事にまとめようと思います。記事公開までもう少々お待ちください。
久しぶりの記事作成でしたが、やはり自分は文章を書くのが好きなのだと思いました。そんなにポンポン記事にするネタが思いつくかは分かりませんが、また何か語りたいことができたときに文字に起こしてみたいと思います。その際には是非当サイトにまた戻って来ていただけたら幸いです。
それでは、また。
Related Post

雑談:JUCEを使って初めてのVSTプラグイン開発!
はぁ、やっとあの言葉を拝むことができたぞ…!! そう、その言葉とは、“Hello World!” 何を言っているのかわからない方のために説明すると、”Hello World […] [...]